Statistical Inference - a/b testing with bootstrapping
In my real-life use case, I deploy multiple models simultaneously and compare their performance to determine which model is most effective. For example, I might look at which model achieves higher accuracy, efficiency, or other relevant metrics based on my objectives. By conducting this comparison, I can identify the model that best meets my needs, ensuring optimal outcomes and improving overall system performance. This approach enables us to make more data-driven decisions about which models to further develop, deploy, or decommission based on their performance metrics.
Let's assume we have deployed two machine learning models, Apollo 1.0 and Apollo 2.0, aimed at reducing the average call duration. If we observe that Apollo 2.0 yields a better reduction in handling time, we must determine whether this improvement is statistically significant or merely due to random variations. This evaluation will help us confirm if we have genuinely enhanced the model or if the observed improvement is coincidental.
You can access the sample Python notebook code.

Model Apollo 1.0
Model Apollo 2.0
Due to confidentiality constraints, I cannot disclose specific objectives or actual results. However, I will outline the general methodology, sample code, and the insights I pursued, which significantly impact the strategic decisions. For simplicity, I refer to the models as Apollo 1.0 and Apollo 2.0. Although I discuss only two models, the A/B testing with bootstrapping methodology I describe can be applied to multiple models.
methodology
Here’s how you might understand it in the context of a dataset with 5,000 phone calls:
1- Make a Bootstrapped Dataset: Begin with your original dataset, which contains records of 5,000 different calls. To create a bootstrapped dataset, randomly select calls from this original dataset, allowing the same call to be selected more than once. Continue this process until your new dataset also includes 5,000 calls. This method of sampling with replacement helps to capture the variability within the data.
2- Calculate the Metric: Calculate the metric of interest (such as average call duration) on this bootstrapped dataset. Since the dataset is constructed to mirror the original size, it maintains the variance and structure of the original data, providing a realistic assessment of the metric.
3- Keep Track of that Calculation: Log every metric calculation from each bootstrapped dataset. This record-keeping is crucial for analyzing the results in the next steps. (Gaussian distribution)
Bootstrapping is a straightforward yet effective statistical technique often used in inference. The core idea is to simulate the distribution by drawing random samples with replacement. This approach is motivated by the concept that the data can estimate its own distribution, allowing us to more accurately discern and analyze that distribution.
By ensuring that each bootstrapped dataset has the same number of calls as the original, you avoid underestimating the variance, thereby preserving the integrity of the statistical analysis. This approach allows you to generate a robust estimation of the metric's distribution, which is critical for understanding the underlying patterns and making informed decisions based on the data.
For generating bootstrapped datasets, the number of simulations should align with your analysis goals and desired precision. Typically, more simulations enhance the stability and accuracy of your estimates but require increased computational resources. As a practical guideline, consider using at least 1,000 bootstraps for basic analysis and up to 10,000 or more for higher precision needs. To efficiently manage a large number of bootstrapped simulations in Python, utilizing parallel computing with the multiprocessing library can be highly effective. Specifically, you can use the Pool class within multiprocessing to create a pool of worker processes.


Original Data Set

...
1- Make a Bootstrapped Dataset (N - many)

2- Calculate the Metric
...
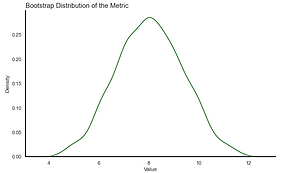
3- Keep Track of that Calculation
analyze
In a customer service scenario, I would prefer a model that not only reduces average call time but also demonstrates less variability (Apollo 2.0), thereby ensuring a consistently efficient customer service experience. By employing A/B testing coupled with bootstrapping, I can more effectively evaluate which of the two Gaussian distributions from my bootstrapped metrics best meets specific needs. This approach ensures that the selected model is not only statistically robust but also practically applicable.
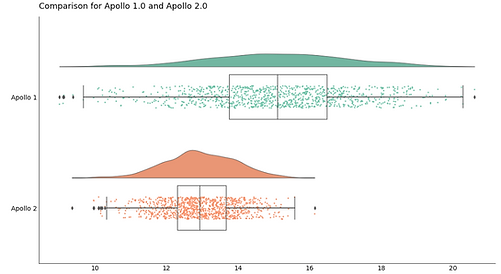

When analyzing two Gaussian distributions from bootstrapped metrics to determine which model performs better, consider a systematic approach that includes comparing means, examining variability, analyzing confidence intervals, conducting statistical tests, and using visual assessments:
-
Examine Variability: Evaluate the consistency of each model's performance through its standard deviation. A lower standard deviation indicates more reliable performance, which can be crucial in settings like manufacturing where predictability is key.
-
Analyze Confidence Intervals: Look at the confidence intervals for precision in estimates. Non-overlapping intervals between the models suggest significant differences in means, indicating one model may be superior.
-
Practical Significance: Consider the real-world implications of differences, such as the impact of slight mean differences in clinical settings or the value of predictability in financial models.
-
Aggregate Metrics: If relevant, develop a composite score that integrates various performance metrics, giving weight to those most critical fr the study's goals.
inspiration
I aimed to develop a statistical model that accurately differentiates actual improvements from random variations in model performance. This was essential for managing multiple models simultaneously during runtime operations, ensuring that observed enhancements in performance are reliable.
Three key resources inspired my project.
First, Ramesh Johari highlighted the unreliability of traditional p-values and confidence intervals in "Stanford Seminar: Peeking at A/B Tests - Why It Matters and What to Do About It." emphasizing the need for more robust methods in my analysis.
Second, in "Jake Vanderplas - Statistics for Hackers - PyCon 2016." Jake Vanderplas introduced alternative statistical solutions, including bootstrapping, providing a practical approach to enhance statistical accuracy.
Third, Allen Downey in "There's Only One Test." advocated for the use of simulation in hypothesis testing, encouraging me to incorporate these techniques into my analysis. Inspired by these experts, I applied their innovative approaches to a real-life dataset to improve the reliability of my statistical findings.
The project effectively separated true performance enhancements from statistical noise, enabling precise adjustments to model deployments. This approach has proven adaptable to various types of data, making it a valuable tool for diverse operational environments.